My Marketing Lives in a Git Repo, and a Bot Opens Pull Requests to Improve It
Our marketing system is a git repo: identity, voice, and channel playbooks as markdown. A nightly job grades posts against their own median, and a weekly job opens a pull request when a pattern repeats. A human merges everything.
On this page
TL;DR: Our marketing system is a git repo. The identity, the voice rules, and the per-channel playbooks all live as markdown. A nightly cron job compares every published post to that channel’s own 30-day median and writes a note when something runs hot or cold. A weekly job reads those notes and, when a pattern repeats three or more times, opens a pull request proposing a playbook change with the receipts attached. A human merges everything, the loop never publishes on its own, and it is never allowed to edit what the brand believes. Here is how it works, and the limits of what it has proven so far.
My marketing lives in a git repo
Every few months I used to rediscover the same marketing lesson. “Right, the posts that open with a number do better.” I had learned that in February and forgotten it by May. The lesson lived in my head, or in a document nobody reopened, which is the same as nowhere.
I run marketing for a two-person software company. The real problem with content at this size is not making it. It is that nothing compounds. Every month restarts from zero because last month’s lessons were never written down anywhere a future decision would trip over them.
So I did the obvious engineer thing and put the whole marketing system in a git repo. The brand identity, the channel playbooks, the voice rules, all of it as plain markdown. Then I wired a loop on top.
The repo is the source of truth
The structure is boring on purpose. There is an identity folder for the stable things: what we believe, how we sound, who we are for. There is a channels folder with a playbook per platform. There is a skills folder of small reusable procedures, and a memory log of what we have learned. Every post we publish carries metadata in its front matter: which product it promotes, which angle it takes, which audience it targets, a tagged link.
None of that is clever. It is just structured, and structure is what lets a machine read the same files a human edits.
The nightly job writes things down
A cron job runs at 2am on an old MacBook. It pulls yesterday’s numbers and compares each post to that channel’s own 30-day median. When a post runs above 1.5x or below 0.5x of the median, it writes a one-paragraph note: what the post was, which angle, and the best guess at why it moved. The notes pile up per channel, plain text, in the repo.
That is the entire point. The lessons stop evaporating. Something that worked in March is still written down in June, with the posts that prove it, instead of getting relearned from scratch.
The weekly job proposes changes
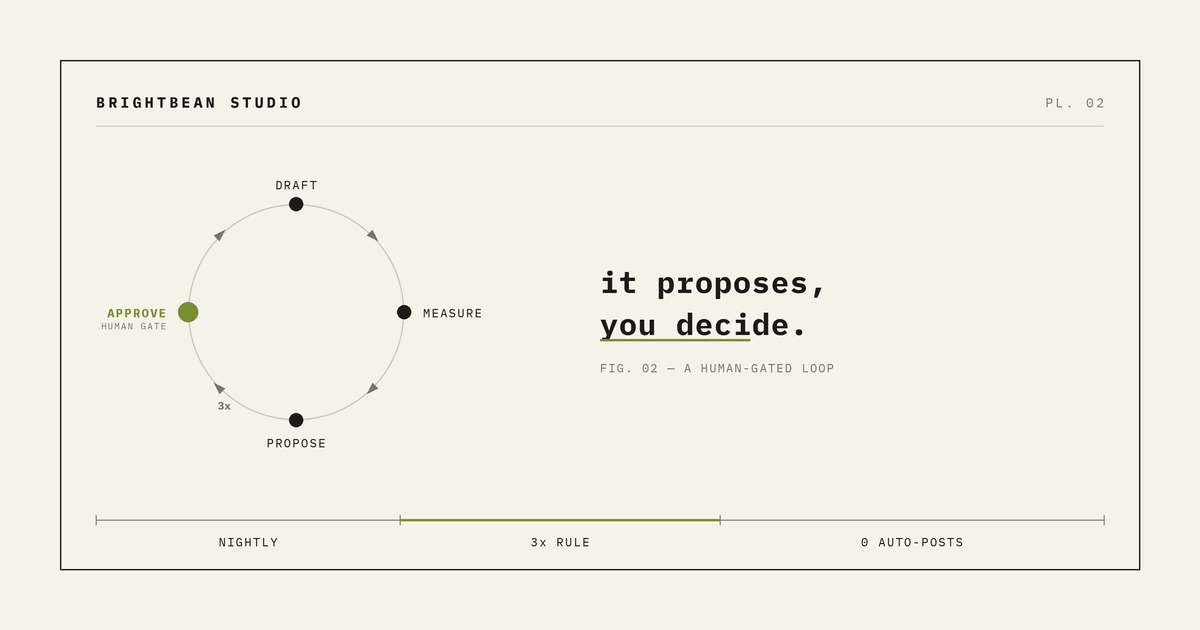
A second job runs once a week. It reads the accumulated notes looking for repetition. If the same pattern shows up three or more times, it opens a pull request: here is a rule worth adding to the playbook, and here are the posts that back it. I review it the way I review code. I merge the ones I believe and close the ones I do not.
A pattern has to earn its way in three times before it is even proposed. That threshold is doing a lot of work. It keeps one lucky post from rewriting the strategy, and it makes every proposed change auditable back to evidence.
The guardrails are the part I actually care about
Two boundaries make this safe to run unattended.
First, it never publishes. Every post stops at a draft a human approves. The token the automation runs with does not carry publish permission, so it cannot post even by mistake. The version of “automated marketing” I actually shipped is this: the machine prepares everything, and a person still hits publish.
Second, it never edits the identity. The voice and the positioning are human-merged only. The loop can propose a tactical playbook tweak. It cannot decide what the company believes or how it sounds. It proposes, it does not decide. Identity should drift in a direction a human chose, not get silently rewritten by a process optimizing for engagement.
The status, plainly
Someone always asks for the graph, so here it is plainly: the mechanics run, but the system has not accumulated months of data yet, so I cannot show you a “this lifted engagement 40%” chart. That number would be made up, and making it up is exactly the thing this whole setup exists to avoid.
What has already changed is smaller and real. The lessons persist. The decisions have receipts. A new channel inherits the accumulated judgment of the old ones instead of starting blind. That is worth more to a two-person team than a dashboard would be.
Why share it
This is not a product. It is how we run our own marketing, and we build in public because the approach is unusual enough to be useful to other small teams. Our actual business is the BrightBean Intelligence YouTube API. Studio, our open-source scheduler, is the free tool that funds itself through that API. The marketing loop is just how two people keep a content operation accountable and compounding without hiring a department.
If your marketing lessons keep evaporating too, you do not need our system. You need version control, a metric you trust, and a rule that the machine proposes while a human decides. The rest is plumbing.